
J Clin Periodontol:基于非临床参数和唾液生物标志物的牙周健康状况机器学习多类筛查工具的开发
2023-09-24 医路坦克 MedSci原创 发表于上海

本文目的是建立一种多层次的牙周病非临床筛查工具,并评估其在鉴别牙周健康、牙龈炎及牙周炎不同阶段的准确性。
 牙周健康状况的检测和鉴别诊断的非临床方法对于更好地预防和管理牙周病(牙龈炎和牙周炎)具有很大的希望,牙周病仍然是人类最重要的健康负担和最常见的非传染性疾病)。疾病控制和预防中心(CDC)和美国牙周病学会(AAP)提出的自我报告措施在不同人群中显示出潜力。最近的努力还集中在使用生物标志物及其组合上。
牙周健康状况的检测和鉴别诊断的非临床方法对于更好地预防和管理牙周病(牙龈炎和牙周炎)具有很大的希望,牙周病仍然是人类最重要的健康负担和最常见的非传染性疾病)。疾病控制和预防中心(CDC)和美国牙周病学会(AAP)提出的自我报告措施在不同人群中显示出潜力。最近的努力还集中在使用生物标志物及其组合上。
尽管存在一些限制,但最近的进展是实质性的。结合多个变量的信息显示出提高准确性的潜力。例如,将人口统计学数据添加到生物标志物数据中,可以改善牙周健康和疾病的多变量诊断模型的性能。我们小组之前的工作已经确定了中文版AAP/CDC问卷中的特定问题、刷牙时牙龈出血(GBoB)和活化基质金属蛋白酶-8 (aMMP-8)水平在鉴别牙周健康、牙龈炎和牙周炎方面的差异效用。中文版CDC/AAP问卷在筛查严重牙周炎方面显示出良好的准确性。然而,该问卷在检测牙龈炎和早期牙周炎方面的帮助较小。最近的研究表明,口腔冲洗液中的GBoB和血红蛋白(Hb)浓度可能是牙龈炎症的前哨信号,对牙周健康和疾病的鉴别具有很大的潜力,特别是对牙龈炎症的检测。尽管GBoB在牙周诊断中具有重要的作用,但它在牙周炎诊断中的准确性较低,这可能是因为牙龈炎和牙周炎都具有这一特征。
基于唾液生物标志物的即时诊断可以即时指示可能的疾病状态,从而允许在诊所外进行牙周健康监测。基质金属蛋白酶(Matrix metalloproteinases, MMPs)是一个调节细胞-基质组成的蛋白酶家族,而MMP-8是牙周病中与胶原降解相关的主要类型的胶原酶。消费者版本的aMMP-8即时检测(POCT)在检测或排除牙周炎方面显示出很大的潜力。然而,仅aMMP-8的准确性已被证明是有限的。
这种方法的一个基本限制是使用为二元条件开发的传统诊断准确性分析。将这些分析应用于多种诊断场景,例如牙周健康、牙龈炎和牙周炎之间的区别,需要对诊断问题进行人工二分:健康和牙龈炎与牙周炎相比,还是健康对抗牙龈炎和牙周炎。确定牙周病例诊断的频谱可能对最佳病例管理有价值。这个问题并不是牙周健康所特有的,而是多阶段疾病的典型问题,已经提出了具体的分析方法。
机器学习是人工智能(AI)和计算机科学的一个子集,它通过以输入输出变量分析的形式构建模型,从而选择最优特征子集并进行自动分类,从而实现疾病诊断和区分。基于机器学习的方法已被用于以更高的准确性识别诊断模式。系统评价已经确定了它们对糖尿病及其并发症以及心血管疾病的潜在益处。初步的方法学报告显示了将人工智能应用于牙周健康人群筛查的潜力
我们假设结合牙周健康-疾病谱的特定非临床特征可以用单一算法提高对牙周健康,牙龈炎和牙周炎及其各个阶段的区分。这项工作的具体目的如下:(i)使用多变量逻辑回归对候选诊断进行初步评估;(ii)基于随机森林(RFs)的筛选工具的开发和内部验证,这是一种机器学习算法,可以正确地将受试者分为三种病例定义(牙周健康、牙龈炎和牙周炎或牙周健康、牙龈炎和I期牙周炎、ii - IV期牙周炎)和六种病例定义(牙周健康、牙龈炎、I期、ii期、III期和IV期牙周炎)。

纳入参与者流程图及研究程序。美国牙周病学会疾病控制与预防中心;aMMP-8,活化基质金属蛋白酶-8;POCT,即时检测;鲍勃,刷牙时流血;刷牙时牙龈出血;TPS,牙膏浆;Hb,血红蛋白。
采用传统的logistic回归分析方法对研究样本(N = 408)中自我报告的非临床参数和唾液生物标志物单独及联合检测牙周健康、牙龈炎、牙周炎和不同阶段牙周炎的诊断准确性进行研究。
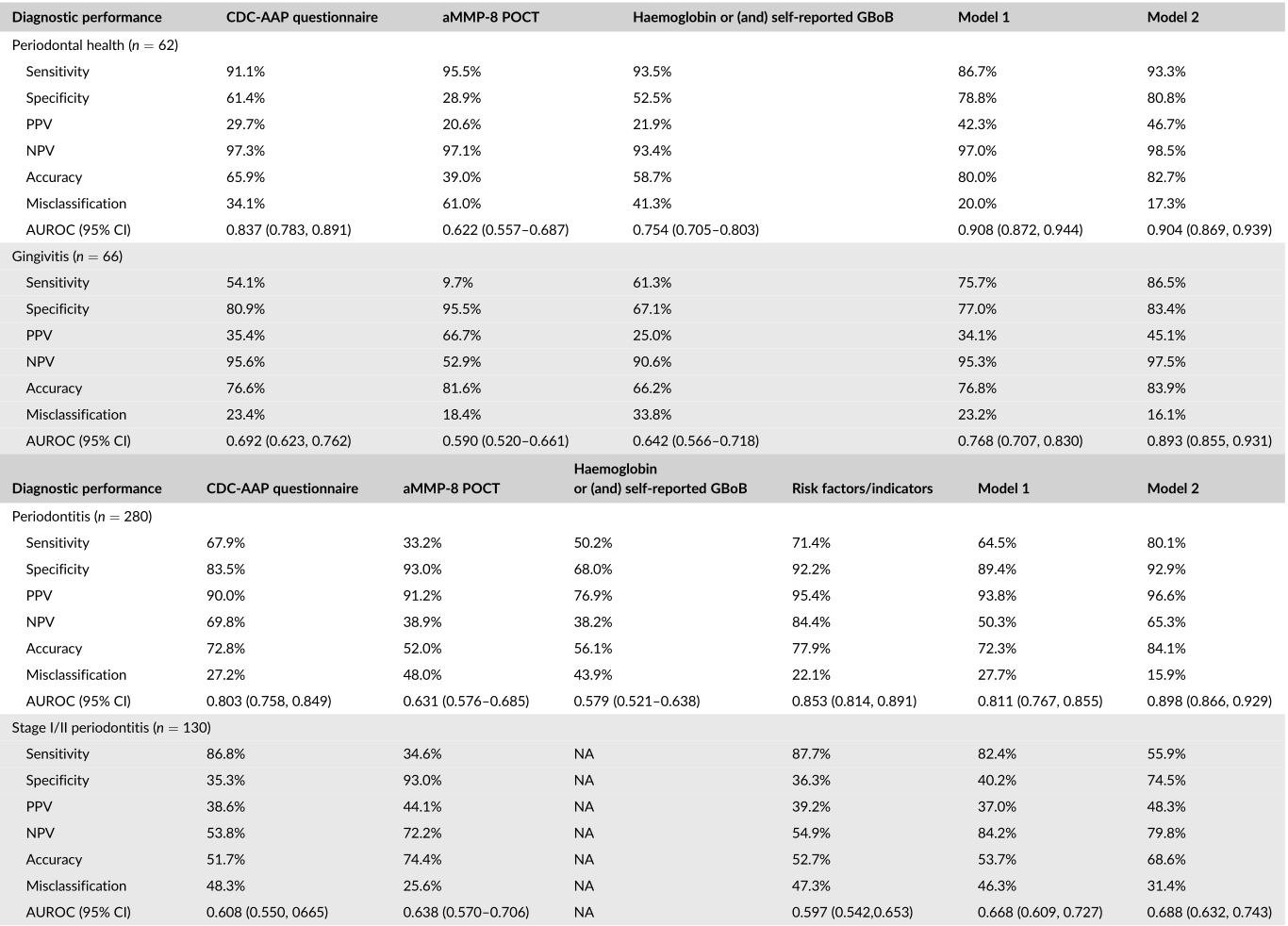
随机森林分类器对牙周健康、牙龈炎和牙周炎三级预测的准确性。(a)牙周健康(1,绿色)、牙龈炎(2,粉红色)和牙周炎(3,红色)。该图显示了灵敏度(左上图)、特异性(左下图)、阳性预测值(中上图)、阴性预测值(中下图)和准确性(右上图)的箱形图。右下的图表显示了预测诊断与实际诊断频率的混淆矩阵。数值是通过平均100次运行得到的。(b)使用Python中的“yellowbrick”包获得的三类随机森林诊断的真阳性率与假阳性率和ROC下面积(AUROC)的接收者工作曲线(详见文本)。(c)随机森林分类中多个因素的相对影响的图表表示。数值是通过平均100次运行得到的。Hb,血红蛋白;基质金属蛋白酶-8。
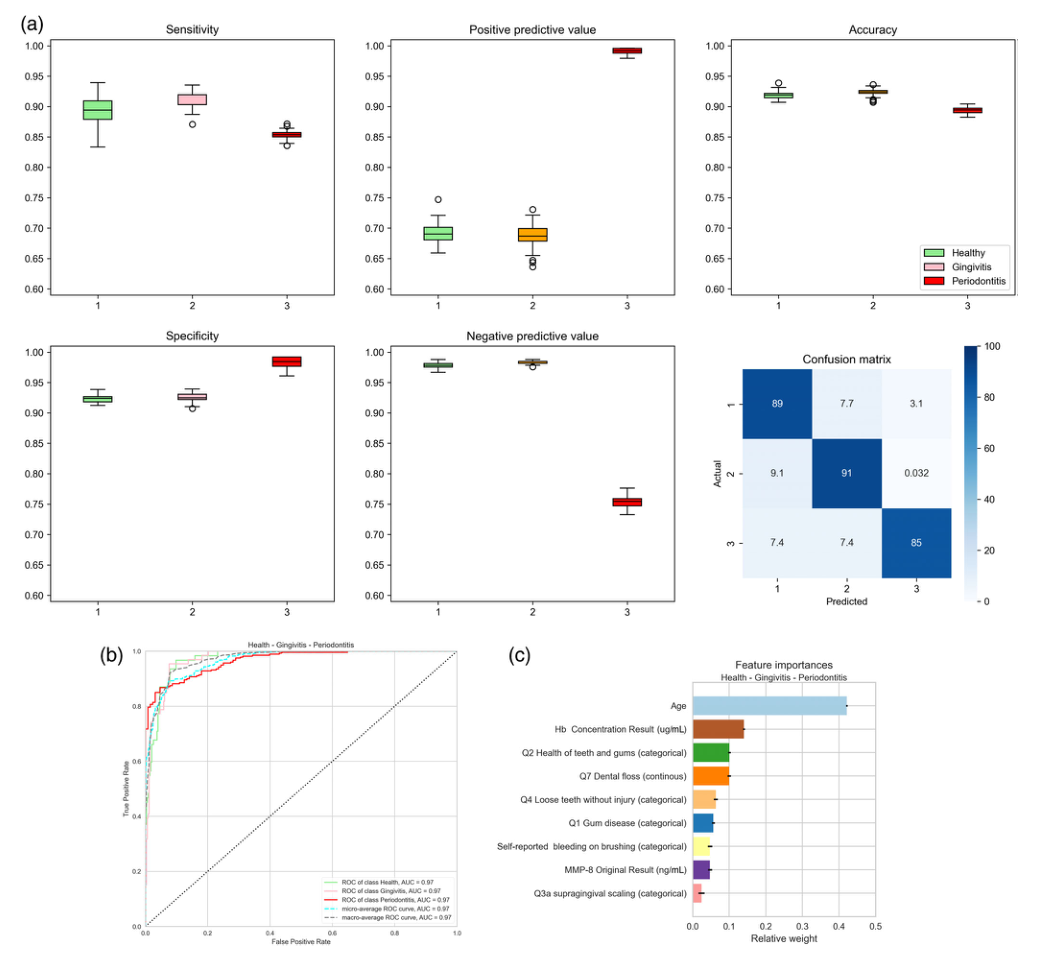
使用随机森林分类器预测牙周健康、牙龈炎和I-IV期牙周炎6级的准确性。
(a)牙周健康(1,绿色)、牙龈炎(2,粉红色)、I期牙周炎(3,橙色)、II期牙周炎(4,浅红色)、III期牙周炎(5,深红色)和IV期牙周炎(6,紫色)。该图显示了灵敏度(左上图)、特异性(左下图)、阳性预测值(中上图)、阴性预测值(中下图)和准确性(右上图)的箱形图。右下的图表显示了预测诊断与实际诊断频率的混淆矩阵。数值是通过平均100次运行得到的。(b)使用Python中的“yellowbrick”包获得的六类随机森林诊断的真阳性率与假阳性率和ROC下面积(AUROC)的接收者工作曲线(详见文本)。(c)六类随机森林分类中多个因素的相对影响的图解表示。数值是通过平均100次运行得到的。Hb,血红蛋白;基质金属蛋白酶-8。

牙周炎+ I期牙周炎和II-IV期牙周炎的随机森林分类器三级预测的准确性(a)牙周健康(1,绿色)、牙龈炎和1级牙周炎(2,橙色)以及II-IV级牙周炎(3,红色)。
该图显示了灵敏度(左上图)、特异性(左下图)、阳性预测值(中上图)、阴性预测值(中下图)和准确性(右上图)的箱形图。右下的图表显示了预测诊断与实际诊断频率的混淆矩阵。数值是通过平均100次运行得到的。(b)使用Python中的“yellowbrick”包获得的三类随机森林诊断的真阳性率与假阳性率和ROC下面积(AUROC)的接收者工作曲线(详见文本)。(c)随机森林三级分类中多个因素的相对影响的图解表示。
数值是通过平均100次运行得到的。Hb,血红蛋白;基质金属蛋白酶-8。
材料和方法:对408名连续受试者进行了一项横断面诊断研究,采用三种非临床指标测试来评估牙周健康疾病谱的不同特征:自我填写问卷、口腔冲洗激活基质金属蛋白酶-8 (aMMP-8)点护理测试(POCT)和刷牙时牙龈出血测定(GBoB)。全口牙周检查为参考标准。牙周诊断是根据2017年牙周疾病和状况分类进行的。采用Logistic回归和随机森林(RF)分析来预测各种牙周诊断,并评估准确性措施。
结果:共纳入48名受试者,包括牙周健康(16.2%)、牙龈炎(15.2%)、牙周炎I期(15.9%)、II期(15.9%)、III期(29.7%)和IV期(7.1%)。9个预测因子,即“牙龈疾病”(Q1)、“牙龈/牙齿健康评级”(Q2)、“牙齿清洁”(Q3a)、“牙齿松动”的症状(Q4)、“使用牙线”(Q7)、aMMP-8 POCT、自我报告的GBoB、血红蛋白和年龄,导致RF分类器的准确性很高。3种(健康、牙龈炎和牙周炎)和6种(健康、牙龈炎、I、II、III和IV期牙周炎)的鉴别准确率较高(ROC曲线下面积> 0.94)。混淆矩阵显示,将牙周炎误诊为健康或牙龈炎的病例少于1%-2%。
结论:基于机器学习的分类器,如RF分析,是非临床环境下牙周健康和疾病多类别评估的有希望的工具。结果需要在适当大小的独立样本中进行外部验证
原始出处:
 Development of a machine learning multiclass screening tool for periodontal health status based on non-clinical parameters and salivary biomarkers.pdf
Development of a machine learning multiclass screening tool for periodontal health status based on non-clinical parameters and salivary biomarkers.pdf
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言





